芯片迭代周期
868|0条评论
芯片技术革新:驱动大模型应用的快速迭代与优化
引言
在人工智能领域,大模型的应用已成为推动技术进步的强大引擎。这些模型,如GPT3、BERT等,以其卓越的性能和广泛的应用前景,引领了AI技术的新浪潮。然而,大模型的训练和部署对计算资源提出了极高的要求,尤其是在芯片技术上的需求。本文将探讨芯片技术的快速迭代如何优化大模型应用,以及这一过程中的关键技术和未来趋势。
芯片技术的发展背景
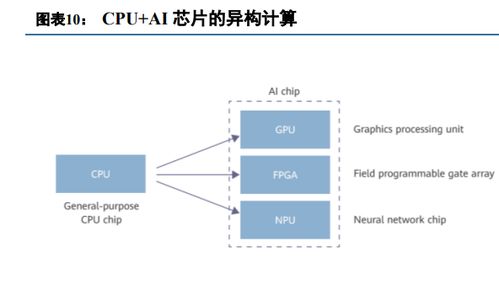
随着人工智能技术的飞速发展,对计算能力的需求呈指数级增长。传统的CPU已无法满足大模型训练的计算需求,因此,GPU、TPU等专用芯片应运而生。这些芯片通过高度并行的计算架构,大幅提升了数据处理速度和效率,成为大模型训练的理想选择。
芯片迭代对大模型应用的影响
1.
性能提升
:新一代芯片通过改进架构设计,提高了计算单元的效率和数据吞吐量,使得大模型的训练时间显著缩短。例如,NVIDIA的A100 GPU相比前代产品,在AI训练任务上的性能提升了数倍。2.
能效优化
:随着芯片技术的迭代,能效比也得到了显著提升。这不仅降低了运行大模型的成本,也使得在能源受限的环境中部署大模型成为可能。3.
定制化设计
:为了更好地服务于大模型的特定需求,芯片设计越来越趋向于定制化。例如,Google的TPU就是专为机器学习任务设计的,其架构优化直接针对神经网络的计算特点。关键技术分析
1.
并行计算技术
:并行计算是提升芯片性能的关键。通过在芯片上集成更多的处理核心,并优化数据流和任务分配,可以显著提高大模型的处理速度。2.
内存技术
:大模型的训练涉及大量数据的读写,因此内存技术的进步将直接影响性能。如HBM(High Bandwidth Memory)技术的应用,大幅提升了内存带宽,减少了数据访问延迟。3.
软件与硬件协同设计
:软件优化与硬件设计的紧密结合,可以进一步释放芯片的潜力。例如,通过深度学习框架与芯片架构的协同优化,可以实现更高效的模型训练和推理。未来趋势
1.
异构计算的进一步发展
:未来的芯片可能会集成更多类型的计算单元,如CPU、GPU、FPGA等,以适应不同类型的计算任务。2.
量子计算的融合
:量子计算在处理复杂计算问题上的潜力巨大,未来可能会与传统芯片技术结合,为大模型提供前所未有的计算能力。3.
可持续性与环保
:随着全球对环保的关注增加,未来的芯片设计将更加注重能效比和环境影响,推动绿色计算的发展。结论
芯片技术的快速迭代是推动大模型应用发展的关键因素。通过不断的技术创新和优化,未来的芯片将提供更强大的计算能力,更低的能耗,以及更优化的定制化服务,从而进一步推动人工智能技术的边界。随着这些技术的不断成熟,我们可以预见一个更加智能、高效的未来。

股市动态
MORE>




- 搜索
- 最近发表
-
- 成都金宇集团,西南经济的璀璨明珠成都
- 探索和讯黄金网,黄金投资的数字化时代
- 雷亚尔对人民币汇率,理解货币兑换的艺术
- 长江电力股份,能源巨轮,照亮未来
- 探索福州市房产交易中心,房产交易的桥梁与指南
- 深入解析基金000001,投资小白的入门指南
- 高盟新材股票,分析、前景与投资建议
- 亚夏汽车股票,投资潜力与市场前景分析
- 深入解析,保险代理人资格证的重要性与获取路径
- 海王英特龙,探索深海的神秘生物
- 保护您的数字资产,了解和使用交易密码的重要性
- 中国平安常青树,稳健投资的典范
- 天安保险股份有限公司,引领行业的创新与服务
- 股票600015,投资界的宝藏还是陷阱?
- 邮票交易所,收藏爱好者的天堂
- 河池化工,化工行业的璀璨明珠
- 江苏银行理财产品,投资智慧与财富增长的桥梁
- 三一重工的全球扩张,收购战略如何塑造未来
- 探索保单查询的奥秘,为何它对你的财务健康至关重要
- 充电桩概念股,新能源时代的投资机遇与挑战